AI i GDPR: Kako pronaći balans između inovacija i zaštite privatnosti?
AI
Kako se sistemi veštačke inteligencije (AI) sve više integrišu u naše svakodnevne živote, pitanja privatnosti, zaštite podataka i etike postaju ključna tema. U eri veštačke inteligencije, privatnost postaje ne samo zakonska obaveza, već i etički imperativ kako za programere, tako i za sve korisnike sistema veštačke inteligencije.
AI tehnologije koje se koriste za identifikaciju sajber pretnji, unapređenje bezbednosti i sprečavanje prevara, mogu imati i drugu, manje poželjnu stranu – masovno prikupljanje podataka, nadzor, praćenje ponašanja lica, profilisanje itd.
U poslednjih nekoliko godina, nadzor zasnovan na veštačkoj inteligenciji postao je predmet ozbiljnih rasprava. Bez jasnih regulativa i transparentnosti, AI može ugroziti privatnost pojedinaca i narušiti druga osnovna ljudska prava umesto da ih štiti.
Evropska unija je pokušala da postavi pravni okvir koji balansira inovacije i zaštite privatnosti tako što je pored Opšte uredbe o zaštiti podataka (GDPR), usvojila i Akt o veštačkoj inteligenciji (AI Act).
AI Act i GDPR zajedno oblikuju način na koji se veštačka inteligencija razvija i koristi, ujedno vodeći računa o zahtevima GDPR-a i privatnosti i zaštiti podataka o ličnosti.
Međutim, iako je cilj ovih propisa usklađivanje razvoja etičke i transparentne veštačke inteligencije, njihova primena može stvoriti izazove i neizvesnosti za pružaoce AI sistema, njihove korisnike, ali subjekte čiji se podaci obrađuju.
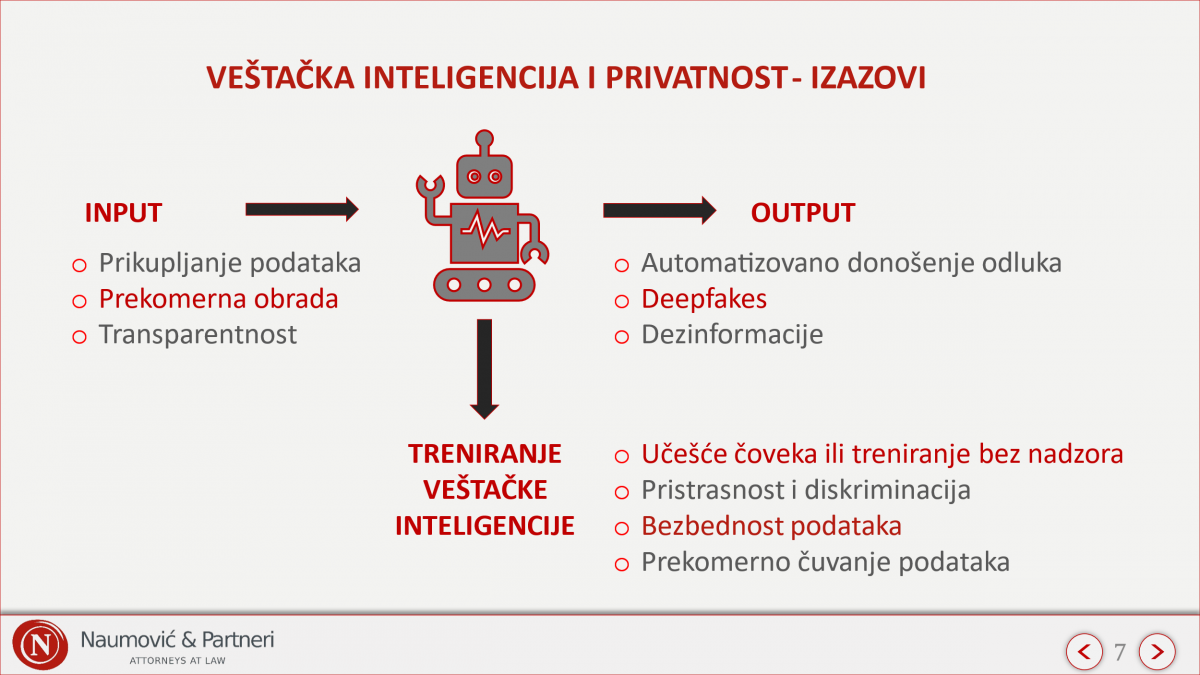
Kako se sistemi veštačke inteligencije oslanjaju na ogromnu količinu podataka, izazovi se javljaju u svim fazama izrade veštačke inteligencije, od unosa podataka, odnosno početne faze razvoja (input), preko procesa treniranja, pa sve do njihove primene u realnom okruženju (output).

1. Prikupljanje informacija od strane AI sistema – pristanak ili web scraping?
Kako smo naveli, razvoj veštačke inteligencije (AI) je nezamisliv bez ogromne količine podataka. Ovi podaci predstavljaju gorivo za algoritme mašinskog učenja. Ipak, način na koji se ti podaci prikupljaju otvara brojna pravna i etička pitanja.
Dva su ključna pristupa za prikupljanje podataka i to: uz pristanak korisnika i korišćenje tehnika poput web scrapinga. Obe metode imaju svoje prednosti i izazove, kako sa pravnog, tako i sa etičkog aspekta.
Pristanak predstavlja jedan od zakonskih načina obrade podataka. Da bi pristanak bio validan, to podrazumeva da isti mora biti informisan, što prevashodno znači da korisnici moraju jasno razumeti kako će se njihovi podaci koristiti. U praksi, ovo je često problematično jer korisnici retko detaljno čitaju obaveštenja pre nego što daju pristanak, a i kada pročitaju često nisu u mogućnosti da razumeju kompleksne procese AI tehnologija.
Takođe, oslanjanje isključivo na pristanak može značajno smanjiti količinu dostupnih podataka jer mnogi korisnici neće dati saglasnost ili će povući pristanak, što može ograničiti razvoj naprednih AI modela koji zavise od velikih količina raznovrsnih podataka.
Dodatno pristanak nije uvek praktičan jer u nekim slučajevima, jer prikupljanje pristanka od svakog pojedinca čiji se podaci koriste može biti logistički neizvodljivo, posebno kada se radi o podacima iz javnih izvora ili podacima prikupljenim sa različitih platformi.
Sa druge strane, web scraping je tehnika automatskog prikupljanja podataka iz javno dostupnih izvora na internetu. Ova metoda omogućava kompanijama da prikupe velike količine podataka brzo i efikasno. Web scraping se često koristi za analizu trendova, profilisanje korisnika, regrutaciju, procenu kreditnog rizika, pa čak i za treniranje AI modela.
Međutim, prema GDPR-u EU, čak i javno dostupni podaci moraju poštovati zahteve GDPR-a ako sadrže podatke o ličnosti, dok sa druge strane, u Sjedinjenim Američkim Državama pravila variraju u zavisnosti od jurisdikcije, ali po pravilu zakoni u SAD-u dozvoljavaju prikupljanje javno dostupnih podataka o ličnosti. Ova pravna nesigurnost stvara izazove za kompanije koje žele da koriste web scraping kao izvor podataka za razvoj veštačke inteligencije.
Jedan od najpoznatijih slučajeva vezanih za web scraping jeste spor između LinkedIn-a i hiQ Labs koji pokazuje različito „tretiranje“ javno dostupnih podataka o ličnosti.
Takođe, još jedan značajan primer je slučaj ClearView AI, kompanije koja je koristila web scraping za prikupljanje milijardi slika sa interneta kako bi razvila sistem za prepoznavanje lica. Italijanski nadzorni organ za zaštitu podataka (Garante) je kaznio ClearView AI sa 20 miliona evra zbog kršenja GDPR-a, uz obavezu da obriše sve prikupljene podatke i zabranu daljeg prikupljanja.
Dakle, iako je web scraping moćna tehnika za prikupljanje podataka, njegov pravni status zavisi od jurisdikcije i specifičnih okolnosti. Sa druge strane, pristanak korisnika ostaje zlatni standard, ali se često suočava sa problemima u praksi.
2. Minimizacija podataka koji se unose u AI sistem kroz anonimizaciju: mit ili stvarnost?
Količina i kvalitet podataka igraju ključnu ulogu u obuci AI modela. Premalo podataka može dovesti do lošeg prepoznavanja obrazaca, dok previše podataka može izazvati preprilagođavanje (overfitting). Preprilagođavanje se događa kada model previše precizno „pamti“ podatke za obuku, umesto da identifikuje opšte obrasce. To može predstavljati rizik za privatnost, jer preprilagođeni modeli mogu nehotice otkriti informacije iz skupa za obuku.
Jedan od ključnih mehanizama za smanjenje broja podataka jeste anonimizacija. U teoriji, anonimizacija podrazumeva tehniku uklanjanja svih podataka iz skupa podataka kako bi se sprečilo povezivanje podataka s pojedincima, odnosno njihovo identifikovanje. Anonimizovani podaci se ne smatraju više podacima o ličnosti jer nemamo identifikovano lice, pa se mogu koristiti bez bilo kakvih ograničenja.
Međutim, postavlja se pitanje – da li su u savremenom svetu anonimizovani podaci zaista anonimni? Iako se smatra da anonimizovani podaci ne mogu identifikovati pojedinca, u praksi se pokazalo da kombinacija različitih podataka može dovesti do ponovne identifikacije.
Naime, javno dostupne informacije na internetu, zajedno sa moćnim algoritmima i računarskim kapacitetima, omogućili su ponovno identifikovanje podataka koji su prethodno bili anonimizovani, odnosno agregacija podataka iz više izvora može dovesti do prepoznavanja identiteta pojedinaca čak i kada su direktni identifikatori uklonjeni.
3. Transparentnost AI sistema – kako postići?
Kako bi lica zadržala kontrolu nad svojim podacima, GDPR postavlja zahtev transparentnosti koji podrazumeva da bi lica morala da budu obaveštena o tome koji podaci, u koju svrhu se prikupljaju, koliko se čuvaju, da li se i kome prenose, kao i sve druge informacije koje su neophodne kako bi pojedinac mogao da bude upoznat šta se „tačno dešava“ sa njenim/njegovim podacima, uključujući i informacije o postojanju automatizovanog donošenja odluke, i, najmanje u tim slučajevima, svrsishodne informacije o logici koja se pri tome koristi, kao i o značaju i očekivanim posledicama te obrade po lice na koje se podaci odnose.
Međutim, AI sistemi, posebno oni zasnovani na dubokom učenju, koriste složene arhitekture koje analiziraju ogromne količine podataka. Ovi modeli obrađuju podatke na način koji često nije lako objašnjiv čak ni samim istraživačima i inženjerima, a ne laicima. Zato korisnici često ne razumeju kako AI donosi odluke, što dodatno otežava transparentnost.
Dodatno, AI modeli često koriste podatke iz različitih izvora – korisničkih unosa, senzora, društvenih mreža, javnih baza podataka i drugih digitalnih tragova, usled čega postaje teško jasno identifikovati njihovo poreklo i način obrade.
Najzad, kompanije koje razvijaju AI modele često žele da zaštite svoje algoritme, trening podatke i metode kao poslovnu tajnu i ne žele da otkrivaju previše informacija, jer bi to moglo ugroziti njihovu konkurentnu prednost, tako da pored svega navedenog postoji konflikt između prava lica na informacije (transparentnost) i prava kompanija na zaštitu svojih tehnologija (zaštitu poverljivih informacija).
4. Treniranje AI sistema – učenje pod nadzorom ili bez nadzora?
Učenje pod nadzorom podrazumeva korišćenje unapred označenih podataka gde ljudski eksperti klasifikuju primere kako bi pomogli AI sistemima da prepoznaju obrasce. Ovaj pristup omogućava visoku preciznost i kontrolu, ali zahteva puno vremena i resursa, jer podaci moraju biti pažljivo pripremljeni i obeleženi.
Kod učenja bez nadzora, algoritmi analiziraju neoznačene podatke i sami otkrivaju obrasce i strukture. Ovaj metod je posebno koristan za prepoznavanje veće grupa podataka (clustering) ili anomalija, a koristi se u oblastima poput analize tržišta, otkrivanja prevara i segmentacije korisnika.
Prednost ovog pristupa jeste što AI može samostalno pronaći obrasce bez potrebe za ručnim označavanjem, što dosta ubrzava proces i smanjuje troškove.
Sa druge strane, postoji veći rizik od preprilagođavanja (overfitting), kao i pristrasnosti pošto model može naučiti neželjene obrasce iz podataka, a nema ljudskog faktora da isto otkloni.
Dodatno, pošto algoritmi sami otkrivaju obrasce u podacima, postoji rizik da se formiraju zaključci koji bi mogli narušiti privatnost ili diskriminisati pojedince. Nedostatak direktne kontrole čini važnim implementaciju zaštitnih mehanizama kako bi se sprečile potencijalne zloupotrebe.
Evropska unija je, kroz novu regulativu o veštačkoj inteligenciji, uvela povećanu kontrolu nad „visokorizičnim“ AI sistemima, koja kontrola bi trebalo da doprinese boljoj zaštiti privatnosti i osiguravanju pravične upotrebe veštačke inteligencije.
5. Pristrasnost i diskriminacija – kako izbeći?
Nepristrasnost AI algoritama direktno zavisi od podataka na kojima su obučeni. Ako skup za obuku nije pravilno formiran, može doći do održavanja postojećih pristrasnosti ili nenamernog uvođenja novih.
Iako odgovorni programeri AI sistema nastoje da uklone ili smanje uticaj štetnih podataka u skupovima za obuku (npr. podataka koji podržavaju dezinformacije, štetne ideje, predrasude, seksizam, nejednakost ili bilo koji oblik diskriminacije), mnogi AI modeli se već treniraju na pristrasnim podacima. Zbog toga su skloniji donošenju pristrasnih odluka (npr. odbijanju zahteva za kredit), što može negativno uticati na korisnike u različitim komercijalnim primenama AI tehnologija.
Zato programeri koji razvijaju i/ili testiraju AI sisteme moraju biti pažljivi da izbegnu obuku diskriminatornih modela i osiguraju da su podaci reprezentativni za različite demografske grupe. Na taj način mogu se minimizovati rizici od nenamernih diskriminacija i osigurati pravičan tretman svih korisnika.
6. Pseudonimizacija kod AI sistema – adekvatna mera zaštite ili iluzija sigurnosti?
AI sistemi zahtevaju ogromne količine podataka i podstiču digitalno „gomilanje“ informacija, zbog čega je još važnije da kompanije koje koriste AI preduzmu strože mere za zaštitu podataka svojih korisnika. Što se više podataka o ličnosti prikuplja i skladišti za razvoj AI sistema, veći je rizik od potencijalnog curenja podataka i drugih povrede podataka.
Pseudonimizacija predstavlja jednu od mera zaštite podataka, gde se podaci o ličnosti zamenjuju pseudonimima prema određenom algoritmu. Međutim, ako se ti pseudonimi ne dodeljuju nasumično, već koriste predvidljiv algoritam, podaci mogu biti ponovo identifikovani.
Međutim, uz pomoć današnjih tehnologija, da li su algoritmi koji vrše pseudonimizaciju toliko bezbedni?
7. Čuvanje podataka u AI sistemu – kada je vreme za brisanje?
Kako smo naveli, AI sistemi zahtevaju ogromne količine podataka i podstiču digitalno gomilanje informacija od kojih se neke koriste za treniranje sistema, a pojedine nisu neophodne.
Kako bi se ispoštovali zahtevi GDPR-a, kada podaci više nisu neophodni za ostvarenje svrhe, u konkretnom slučaju za treniranje sistema veštačke inteligencije, potrebno je takve podatke brisati.
Međutim, brisanje podataka o ličnosti iz AI sistema nije jednostavan proces, i to iz više tehničkih, pravnih i praktičnih razloga.
Najpre, često je teško razdvojiti podatke o ličnosti od drugih podataka kako se nalaze u AI sistemu. Dodatno, kada se jednom prikupe i unesu u sistem, podaci često postaju duboko integrisani u model, što otežava njihovo potpuno uklanjanje.
Najzad, ukoliko su podaci prikupljeni na osnovu pristanka, ukoliko lice povuče pristanak, podaci bi u skladu sa GDPR-om morali da se brišu. Problem je što većina današnjih AI sistema nije dizajnirana sa mogućnošću selektivnog „zaboravljanja“ određenih podataka. Ako bi trebalo ukloniti podatke određenog korisnika, često bi bilo potrebno ponovno obučiti ceo model, što može biti izuzetno skupo i vremenski zahtevno.
8. Automatizovano donošenje odluka – kada je moguće i pod kojim uslovima?
Regulativa poput Opšte uredbe o zaštiti podataka (GDPR) i sličnih zakonskih okvira nastoji da zaštiti prava pojedinaca i obezbedi da automatizovano odlučivanje ne narušava njihova osnovna prava i slobode.
Saglasno GDPR-u, lice na koje se podaci odnose ima pravo da se na njega ne primenjuje odluka doneta isključivo na osnovu automatizovane obrade, uključujući i profilisanje, ako se tom odlukom proizvode pravne posledice po to lice ili ta odluka značajno utiče na njegov položaj.
Automatizovano donošenje odluka može imati ozbiljne posledice na pravni status i društveni položaj pojedinaca. Odluke koje proizvode pravne posledice uključuju recimo:
- Raskid ugovora,
- Odbijanje socijalnih beneficija,
- Odbijanje ulaska u zemlju ili dodelu državljanstva.
Pored toga, postoje odluke koje ne menjaju formalni pravni status, ali značajno utiču na pojedinca, kao što su:
- Odbijanje zahteva za kredit,
- Automatsko filtriranje (odbijanje) kandidata u procesu zapošljavanja bez ljudske procene,
- Ograničavanje pristupa obrazovnim ili zdravstvenim uslugama.
Najpoznatiji primeri gde su kompanije kažnjene zbog nepoštovanja odredbi GDPR-a o automatizovanom donošenju odluka su Schufa slučaj i Foodinho slučaj.
Izuzetno, automatizovane odluke su dozvoljene samo ako:
- su neophodne za izvršenje ugovora između pojedinca i organizacije,
- su zasnovane na zakonu koji propisuje odgovarajuće mere zaštite,
- ili se sprovode uz izričit pristanak pojedinca.
Kako bi se smanjili negativni efekti automatizovanih odluka, neophodno je obezbediti:
- Transparentnost algoritama i jasno objašnjenje kriterijuma donošenja odluka,
- Mogućnost ljudske revizije odluka,
- Primenu mera za smanjenje diskriminacije i pristrasnosti,
- Efikasne mehanizme žalbi i osporavanja odluka.
Slično kao i GDPR, EU Akt o veštačkoj inteligenciji (AI Act) nastoji da zaštiti osnovna prava i slobode omogućavanjem odgovarajućeg ljudskog nadzora i intervencije, poznatog kao princip „čovek u sistemu“ („human-in-the-loop“). AI Act zahteva da visokorizični AI sistemi budu dizajnirani i razvijeni na način koji omogućava efikasan nadzor od strane ljudi tokom njihove upotrebe. To uključuje integraciju odgovarajućih alata za interakciju između čoveka i mašine. Drugim rečima, provajderi AI sistema moraju primeniti pristup „ljudskog nadzora kroz dizajn“ („human-oversight-by-design“) kako bi osigurali kontrolu nad radom AI sistema.
9. Deepfake AI tehnologija – šta je realnost?
Deepfake označava AI-generisanu ili manipulisanu sliku, zvuk ili video sadržaj koji podseća na postojeće osobe, objekte, mesta ili događaje i koji može izgledati autentično, iako je zapravo lažan.
Generativni modeli, koriste se za stvaranje lažnog sadržaja koji izgleda uverljivo. Ovi modeli omogućavaju kreiranje realističnih slika i video zapisa koji mogu obmanuti javnost. Takvi sintetički podaci se koriste za:
- Dezinformaciju,
- Krađu identiteta,
- Manipulisanje javnim mnjenjem,
- Stvaranje lažnih narativa koji mogu uticati na reputaciju pojedinaca i institucija.
Ovi sadržaji mogu ozbiljno uticati na poverenje u informacije, privatnost pojedinaca i društvo u celini.
U politici su deepfake sadržaji već korišćeni za širenje dezinformacija. Jedan od primera je manipulisan video bivšeg predsednika SAD-a Baraka Obame, u kojem on izgovara stvari koje nikada nije rekao. Takođe, poznati su slučajevi glumaca, muzičara i drugih javnih ličnosti koji su izvrgnuti deepfake tehnologiji. Ovakve manipulacije mogu imati ozbiljne posledice po reputaciju tih lica, ali i po demokratske procese i javno poverenje u medije.
Kako bi se deepfake stavili pod regulatorne okvire i minimizovali rizici koje isti proizvode, AI Akt propisuje da osobe koje koriste AI sisteme za generisanje ili manipulaciju slikama, zvukom ili video sadržajem moraju jasno naznačiti da je sadržaj veštački generisan.
Sa druge strane, s obzirom da slika, video snimak, glas i drugo obeležje lica predstavljaju podatak o ličnosti, GDPR zahteva pristanak lica za njihovo dalje korišćenje, što podrazumeva i za pravljenje deepfake. Kada se deepfake tehnologija koristi za manipulaciju nečijim likom ili glasom bez njihove dozvole, to predstavlja kršenje privatnosti.
Deepfake tehnologija donosi ozbiljne izazove po poverenje u digitalne sadržaje, privatnost i sigurnost pojedinaca. Dok regulative pokušavaju da postave jasne granice za njenu upotrebu, korisnici moraju biti svesni rizika i razviti kritički odnos prema informacijama koje konzumiraju na internetu. Edukacija i tehnološka rešenja za detekciju deepfake sadržaja igraće ključnu ulogu u borbi protiv zloupotrebe ove tehnologije.
10. Širenje dezinformacija i manipulacija uz AI – kome verovati?
Naveli smo da se deepfake, ali i druge slične tehnologije i metode mogu koristiti za širenje dezinformacija, manipulaciju javnim mišljenjem i obmanjivanje pojedinaca na masovnom nivou. Podaci pojedinaca se iskorišćavaju za kreiranje visoko personalizovanog i ubedljivog sadržaja.
Snažne mere zaštite podataka mogu pomoći u sprečavanju manipulacije vođene AI sistemima. Ograničavanjem neovlašćenog pristupa podacima o ličnosti, zaštita privatnosti može smanjiti rizik da AI bude korišćen za uticaj na donošenje odluka bez pristanka korisnika.
11. Privatnost kao imperativ razvoja veštačke inteligencije
Pronalaženje balansa između tehnološke inovacije i zaštite privatnosti ključno je za izgradnju budućnosti u kojoj tehnologija unapređuje naše blagostanje. Veštačka inteligencija nije neizbežni neprijatelj, već moćan alat koji može ne samo obezbediti efikasno upravljanje podacima, već i pomoći u zaštiti podataka. Različiti modeli veštačke inteligencije nose svoje specifične rizike po privatnost, ali to samo naglašava potrebu da ih koristimo na mudar i odgovoran način.
Iako EU nastoji da obezbedi bezbednu i etičku primenu AI tehnologija, izazovi u implementaciji ovih regulativa ostaju. Ključno pitanje je kako će se AI industrija prilagoditi novim propisima, a istovremeno zadržati prostor za inovacije i razvoj.
Sa druge strane se postavlja pitanje da li su potrebni novi zakoni za rešavanje problema privatnosti u vezi sa veštačkom inteligencijom? Nesumnjivo da postojeći zakoni o zaštiti podataka o ličnosti ne idu u korak sa tehnologijom i nisu adekvatno prilagođeni za rešavanje izazova koje AI donosi. Iako novi zakoni o veštačkoj inteligenciji mogu pomoći, AI jasno pokazuje da je krajnje vreme za temeljno preispitivanje zakona o privatnosti i zaštiti podataka o ličnosti.



{kind=link}
{kind=link}
{kind=link}